Hi all,
I have finished this at home now . Some of my findings are pretty good and will most likely make us go ahead on next Thursday for BW.
I have set up the same monitors (the same way both f5 have been configured in PROD Norwest) without the XFF header being added into the APP VIP as per below:
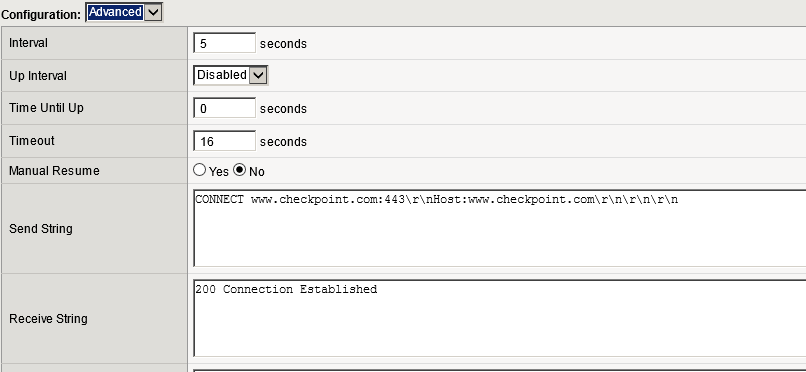
Client F5’s:
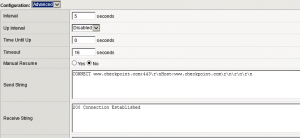
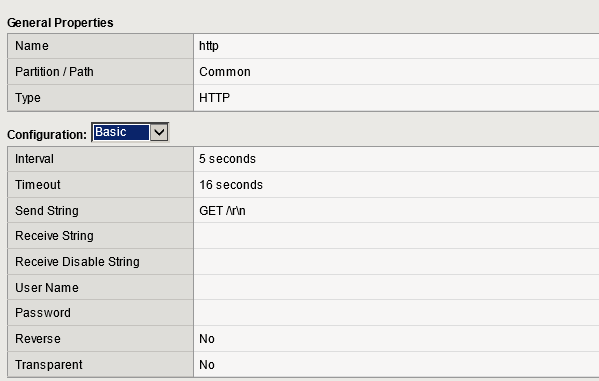
Our Managed F5’s
Using basic http (default)
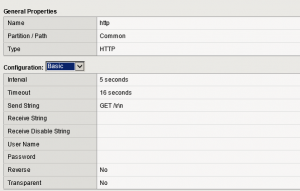
I can see the requests passing through the APP proxy for both monitors and marking them as green…
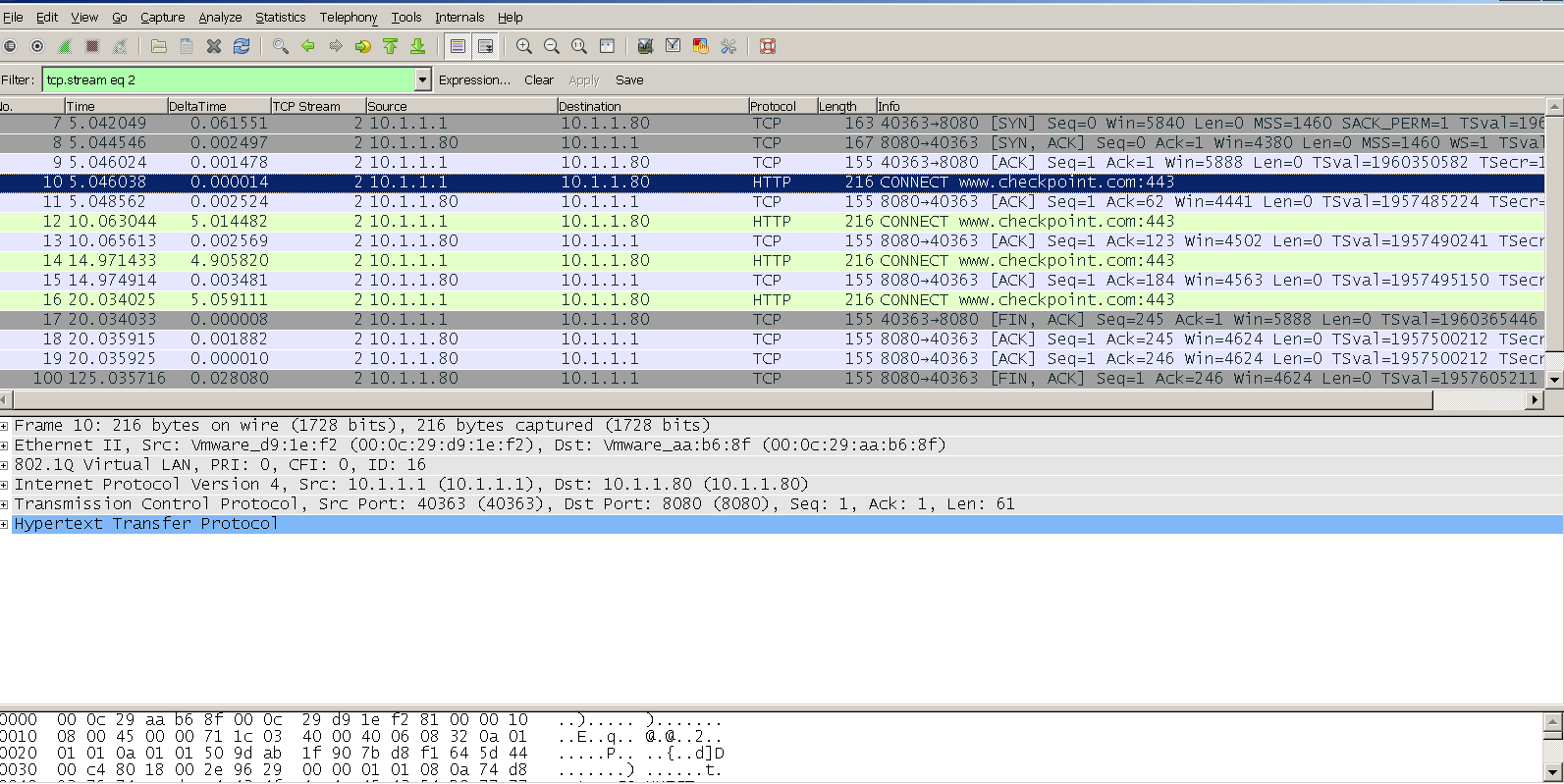
Client F5’s request
start transaction ——————-
CPL Evaluation Trace: transaction ID=733
transaction type: qualifier-index=1 name=http service=SG-HTTP-Service module=HTTP
MATCH: authenticate(no)
MATCH: ALLOW
miss : condition=X-Forwarded-For_Suppressed_URLs
MATCH: url.domain=//www.google.com.au/ cache(no)
MATCH: trace.request(yes) trace.rules(all) trace.destination(Trace)
connection: service.name=Explicit HTTP client.address=192.168.2.199 proxy.port=8080
time: 2014-11-03 08:29:30 UTC
CONNECT tcp://www.checkpoint.com:443/
DNS lookup was unrestricted
user: unauthenticated
authentication status=’not_attempted’ authorization status=’not_attempted’
server.response.code: 0
client.response.code: 200
application.name: unavailable
application.operation: unavailable
caching-decisions: cache(no)
DSCP client outbound: 65
DSCP server outbound: 65
Transaction timing: total-transaction-time 1217 ms
Checkpoint timings:
new-connection: start 1 elapsed 0 ms
client-in: start 1 elapsed 0 ms
server-out: start 1 elapsed 0 ms
access-logging: start 1217 elapsed 0 ms
stop-transaction: start 1217 elapsed 0 ms
Total Policy evaluation time: 0 ms
url_categorization not completed
client connection: first-response-byte 0 last-response-byte 1217
stop transaction ——————–
Our Managed F5’s request
start transaction ——————-
CPL Evaluation Trace: transaction ID=734
transaction type: qualifier-index=1 name=http service=SG-HTTP-Service module=HTTP
MATCH: authenticate(no)
MATCH: ALLOW
miss : condition=X-Forwarded-For_Suppressed_URLs
miss : url.domain=//www.google.com.au/
MATCH: trace.request(yes) trace.rules(all) trace.destination(Trace)
connection: service.name=Explicit HTTP client.address=192.168.2.199 proxy.port=8080
time: 2014-11-03 08:29:31 UTC
GET https://192.168.2.200:8080/
RDNS lookup was unrestricted
user: unauthenticated
authentication status=’not_attempted’ authorization status=’not_attempted’
EXCEPTION(invalid_request): Request could not be handled
server.response.code: 0
client.response.code: 200
application.name: unavailable
application.operation: unavailable
DSCP client outbound: 65
DSCP server outbound: 65
Transaction timing: total-transaction-time 486 ms
Checkpoint timings:
new-connection: start 1 elapsed 0 ms
client-in: start 1 elapsed 485 ms
server-out: start 486 elapsed 0 ms
client-out-terminated: start 486 elapsed 0 ms
access-logging: start 486 elapsed 0 ms
stop-transaction: start 486 elapsed 0 ms
Total Policy evaluation time: 485 ms
url_categorization not completed
server connection: start 486
DNS Lookup: start 486 elapsed 0 ms
server connection: connected 486
client connection: first-response-byte 0 last-response-byte 486
Total time added: 485 ms
Total latency to first byte: 485 ms
Request latency: 485 ms
OCS connect time: 0 ms
Response latency (first byte): 0 ms
Response latency (last byte): 0 ms
stop transaction ——————–
inserting the XFF into the http header for the APP proxy it has the same behavior experienced in PROD as down so I was able to replicate the issue:

Getting some packet captures that’s what I can see is a replica during the troubleshooting session:
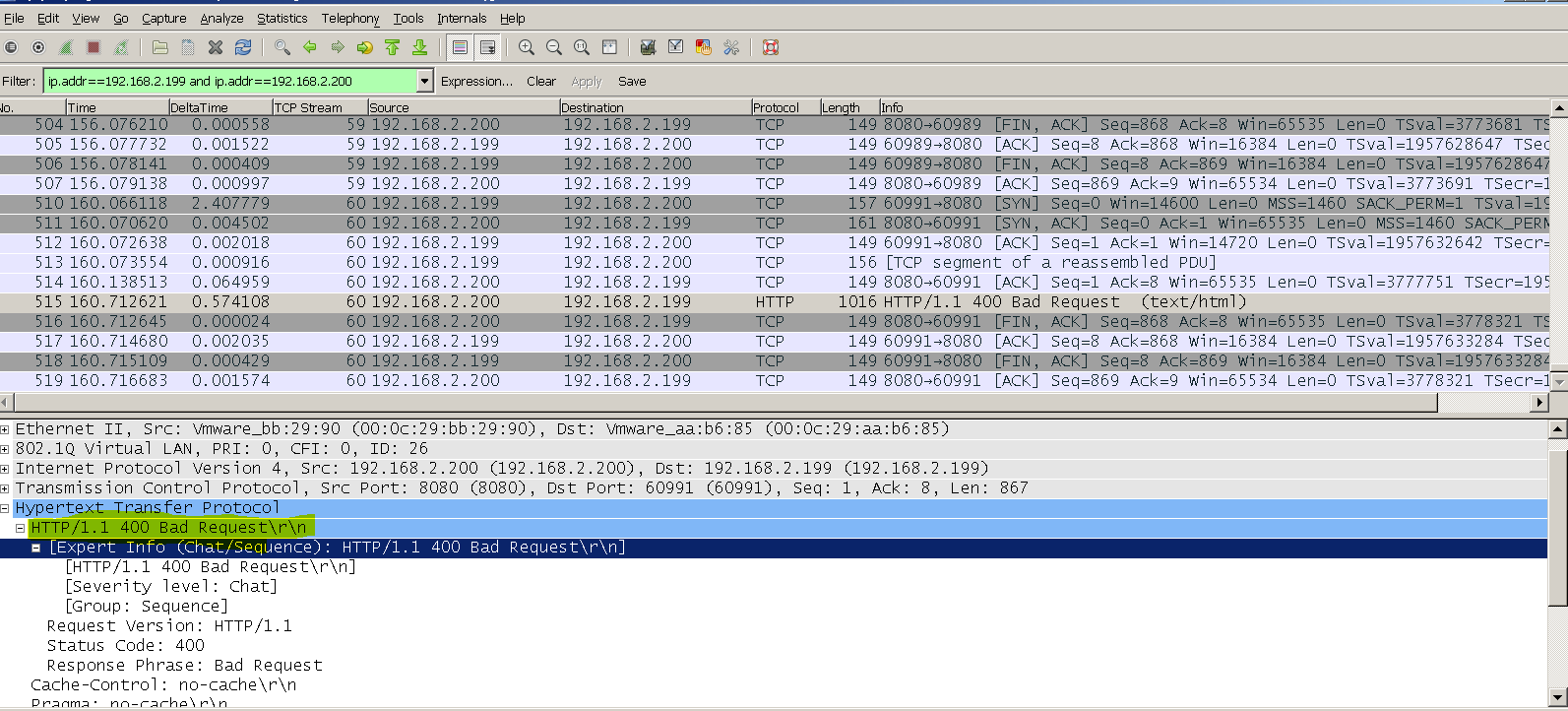
No response from our Managed F5’s.
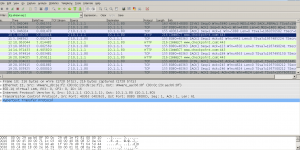
And looking at the conversation from our Managed F5 to the APP proxy is stating BAD REQUEST.
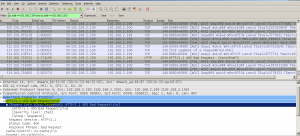
Changing the monitor to what it should be using http1.1.
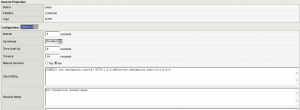
Life is good again 🙂

start transaction ——————-
CPL Evaluation Trace: transaction ID=1723
transaction type: qualifier-index=1 name=http service=SG-HTTP-Service module=HTTP
MATCH: authenticate(no)
MATCH: ALLOW
miss : condition=X-Forwarded-For_Suppressed_URLs
MATCH: cache(no)
MATCH: trace.request(yes) trace.rules(all) trace.destination(Trace)
connection: service.name=Explicit HTTP client.address=192.168.2.199 proxy.port=8080
time: 2014-11-03 09:05:32 UTC
CONNECT tcp://www.checkpoint.com:443/
DNS lookup was unrestricted
user: unauthenticated
authentication status=’not_attempted’ authorization status=’not_attempted’
server.response.code: 0
client.response.code: 200
application.name: unavailable
application.operation: unavailable
caching-decisions: cache(no)
DSCP client outbound: 65
DSCP server outbound: 65
Transaction timing: total-transaction-time 465 ms
Checkpoint timings:
new-connection: start 1 elapsed 0 ms
client-in: start 1 elapsed 0 ms
server-out: start 1 elapsed 0 ms
access-logging: start 465 elapsed 0 ms
stop-transaction: start 465 elapsed 0 ms
Total Policy evaluation time: 0 ms
url_categorization not completed
client connection: first-response-byte 0 last-response-byte 465
stop transaction ——————–
explanation: A client MUST include a Host header field in all HTTP/1.1 request messages . If the requested URI does not include an Internet host name for the service being requested, then the Host header field MUST be given with an empty value. An HTTP/1.1 proxy MUST ensure that any request message it forwards does contain an appropriate Host header field that identifies the service being requested by the proxy. All Internet-based HTTP/1.1 servers MUST respond with a 400 (Bad Request) status code to any HTTP/1.1 request message which lacks a Host header field.
Besides I reckon once we have included XFF into the VIP is not supported by HTTP 1.0 (but I haven’t researched on that).